
Practical strategies for integrating AI/ML into your AWS cloud environment without compromising cost, security, or agility
iShift • October 2025 • 8-minute read
At a Glance
Generative AI is reshaping how businesses compete. However, deploying it successfully on AWS requires more than spinning up GPU instances. This guide walks you through proven strategies for integrating AI workloads while maintaining security, controlling costs, and delivering measurable business impact. It covers quick-win pilots using Amazon Bedrock to enterprise-scale MLOps platform scenarios.
Key Takeaway
Start with pre-trained foundation models to prove value in weeks, then scale to custom solutions as your needs mature.
Who Should Read This
- CTOs and Engineering Leaders planning AI adoption roadmaps
- Cloud Architects designing secure, scalable AI infrastructure
- Data Science Teams ready to move from experimentation to production
- FinOps Professionals managing AI/ML cloud costs
- Compliance Officers ensuring AI governance and regulatory adherence
Why Generative AI in the Cloud Matters Now
Your competitors are already using AI to win customers.
While you’re reading this, companies in your industry are deploying chatbots that resolve customer issues in seconds, fraud detection systems that catch threats in real-time, and predictive models that optimize supply chains automatically. According to Gartner, 74% of executives say generative AI will be critical to their competitive advantage within the next 2 years.
But here’s the challenge: AI isn’t just another cloud workload. Unlike traditional applications, AI demands careful orchestration of GPU resources, strict data governance, seamless integration with existing systems, and constant monitoring for model drift. Done right, AI/ML on AWS becomes a force multiplier for innovation. Done poorly, it creates runaway costs, security vulnerabilities, and compliance headaches.
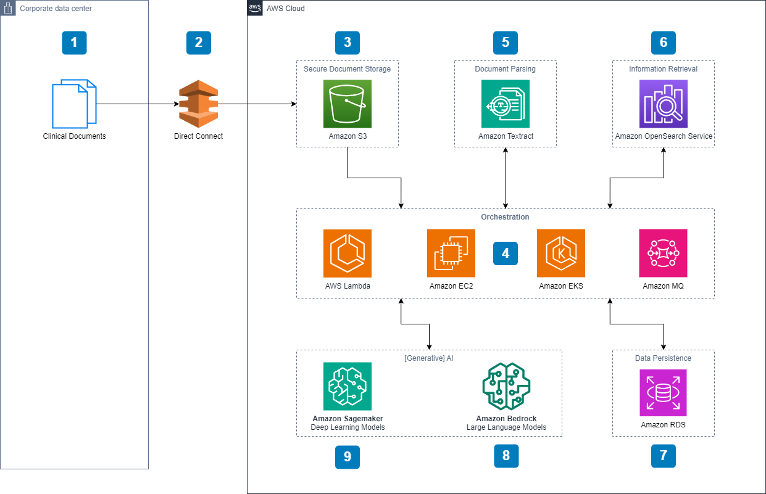
4 Core Strategies for AI/ML Integration on AWS
1. Assess and Prioritize AI Use Cases
Not all AI initiatives deliver equal ROI. Start with the end in mind.
The right way to prioritize:
- Business impact first: Will this reduce costs, increase revenue, or improve customer satisfaction?
- Data availability second: Do you have quality data to train models?
- Complexity third: Can pre-trained models solve this, or do you need custom development?
2. Leverage AWS-Managed Services
AWS offers AI/ML services for every maturity level: from zero-code solutions to fully customizable platforms. The key is to choose the right tool for your current stage.
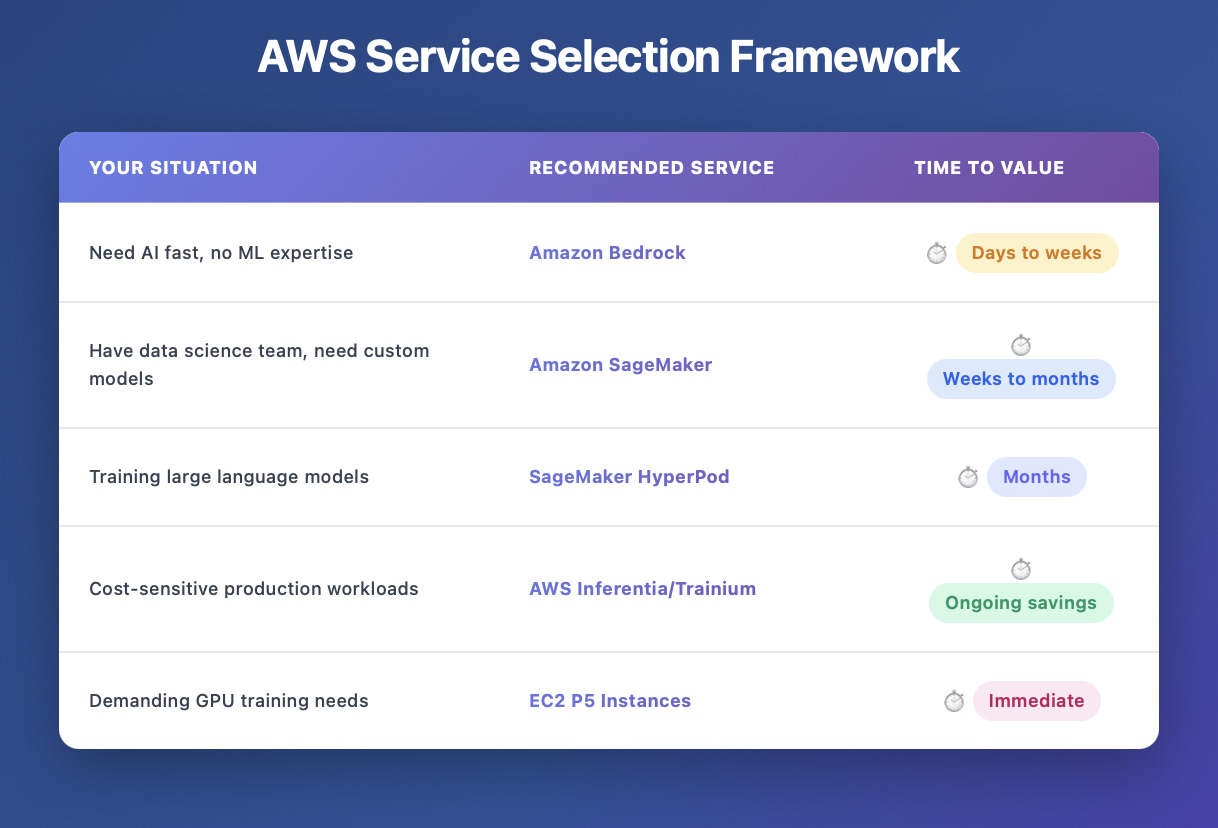
3. Address Security and Compliance from Day One
Security isn’t an afterthought, it’s a foundation. AI workloads often process your most sensitive data: customer personally identifiable information (PII), financial transactions, healthcare records, and proprietary business information.
Security checklist for AI workloads:
- Encryption: At rest (S3, EBS) and in transit (TLS)
- IAM controls: Principle of least privilege for model access
- VPC isolation: Keep training data off the public internet
- Compliance frameworks: HIPAA, GDPR, SOC 2, PCI-DSS alignment
4. Build Scalable Data Foundations
Your AI models are only as good as your data infrastructure. The most common reason AI projects fail isn’t model performance. It’s data quality and availability.
AWS AI Services Deep Dive: Which One Should You Choose?
Amazon Bedrock: The Fast-Track Option
Best for: Teams that need AI functionality quickly without ML expertise. Bedrock provides access to pre-trained foundation models from Anthropic (Claude), Meta (Llama), Stability AI, and others through a simple API.
Amazon SageMaker: The Custom Solution Platform
Best for: Data science teams building custom models with specific business requirements. SageMaker is a comprehensive ML platform with built-in algorithms, automated model tuning, MLOps capabilities, and managed deployment endpoints.
Real-World Results: Financial Services Case Study
A global financial services firm needed to detect fraudulent transactions in real-time—without disrupting legitimate customer purchases.

Key success factors:
- Started with a well-defined use case with clear ROI
- Built security and compliance into the architecture from day one
- Used managed services (SageMaker) to accelerate time-to-production
Your 5-Step Implementation Roadmap
- Conduct an AI Readiness Assessment: Evaluate data maturity and AWS infrastructure (1-2 weeks).
- Start with a Contained Pilot: Choose a high-impact, low-complexity use case like a chatbot (4-8 weeks).
- Build a Phased Roadmap: Scale systematically from Bedrock to SageMaker.
- Align AI KPIs to Business Outcomes: Measure success by ROI and customer satisfaction, not just accuracy.
- Implement FinOps for AI: Use Cost Explorer and Savings Plans to prevent runaway costs.
Common Questions Answered
How much does AI on AWS actually cost?
It varies. A simple Bedrock chatbot might cost $500/month, while large custom models can cost $10,000-100,000+ per training run. The key is starting small, measuring ROI, and scaling what works.
Do we need a data science team to get started?
No, not if you start with Amazon Bedrock. You only need basic engineering skills. Custom models will require ML expertise later.
How do we ensure our AI models are secure and compliant?
Security must be built in from day one, not added later. Key requirements:
- Encrypt all data (S3, EBS) at rest and in transit
- Use VPC isolation to keep training data off the public internet
- Implement IAM least-privilege access controls
- Enable CloudTrail for audit logging
- Document data lineage
If you have strict data residency requirements, starting in AWS will accelerate your timeline and reduce risk.
Ready to Scale AI Securely on AWS?
Deploying AI successfully isn’t about having the best algorithms. It’s about having the right strategy, architecture, and partnerships.
iShift helps enterprises accelerate their AI journey on AWS with:
- AI readiness assessments and roadmap development
- Secure, scalable architecture design
- Pilot implementation and production deployment
- MLOps platform setup and team training
- Ongoing optimization and cost management
Unsure how to start? Schedule a consultation with our AWS AI experts to discuss your specific use case and get a customized roadmap.
Schedule Your Free Consultation →


